47. The Kalman Filter and Vector Autoregressions#
47.1. Overview#
This lecture derives the Kalman filter for a linear Gaussian state space system and then uses it to construct vector autoregressions (VARs).
Our approach rests on repeated applications of the population linear least squares projection formula, the insight that computing a conditional expectation of a jointly normal random vector is the same as running a population OLS regression.
The lecture covers:
deriving the Kalman filter recursions from first principles
the matrix Riccati difference equation governing conditional covariance matrices
the innovations representation and the Gram-Schmidt whitening property
the structure of a hidden Markov model
the likelihood function for a state space system and its role in maximum likelihood and Bayesian estimation
how the time-invariant Kalman filter generates a vector autoregression
why the Kalman filter is an essential tool for interpreting VARs estimated from economic data
47.2. The state space system#
The Kalman filter applies to the state space system for \(t \geq 0\):
where
\(x_t\) is an \(n \times 1\) state vector (hidden, unobserved)
\(y_t\) is an \(m \times 1\) vector of signals on the hidden state (observed)
\(w_{t+1}\) is a \(p \times 1\) i.i.d. sequence of normal random variables with mean \(0\) and identity covariance matrix
\(v_t\) is an i.i.d. sequence of normal random variables with mean zero and covariance matrix \(R\)
\(w_{t+1}\) and \(v_s\) are orthogonal for all \(t+1\) and \(s \geq 0\)
The initial state satisfies
We observe \(y_t, \ldots, y_0\) but not \(x_t, \ldots, x_0\) at time \(t\), and we know all first and second moments implied by (47.1) and (47.2).
47.3. The Kalman filter#
47.3.1. Starting distribution#
Working forward in time starting at \(t = 0\), before observing \(y_0\), the specification (47.1)-(47.2) implies that the marginal distribution of \(y_0\) is
For \(t \geq 0\) let \(y^t = [y_t, y_{t-1}, \ldots, y_0]\).
We want a convenient recursive representation of the conditional distribution of \(y_t\) given history \(y^{t-1}\).
The Kalman filter attains this by constructing recursive formulas for \(\hat{x}_t\) and \(\Sigma_t\) such that the distribution of \(y_t\) conditional on \(y^{t-1}\) generalises (47.3) to
for \(t \geq 1\), where the distribution of \(x_t\) conditional on \(y^{t-1}\) is \(\mathcal{N}(\hat{x}_t, \Sigma_t)\).
The objects \(\hat{x}_t\) and \(\Sigma_t\) characterise the population regression
and the conditional covariance matrix
47.3.2. Derivation#
At each date, our approach is to regress what we do not know on what we know.
Note
Because our assumptions imply that \(\{x_t, y_t\}_{t=0}^\infty\) is a jointly normal stochastic process, linear least squares regressions equal conditional mathematical expectations — each step below is an application of Bayes’ law.
Under the weaker assumption that all means and covariances exist without joint normality, the same calculations yield “wide-sense conditional expectations” that coincide with true conditional expectations only when those conditional expectations are linear.
Arrive at \(t = 0\) knowing \(\hat{x}_0\) and \(\Sigma_0\).
Innovation: The information about \(x_0\) in \(y_0\) that is new relative to \((\hat{x}_0, \Sigma_0)\) is the innovation
Updating beliefs about \(x_0\): The conditional mean \(\mathbb{E}[x_0 \mid y_0] = \hat{x}_0 + L_0(y_0 - G\hat{x}_0)\) satisfies the population regression formula
where \(\eta\) is the least squares residual.
Orthogonality of \(\eta\) to \((y_0 - G\hat{x}_0)\) pins down \(L_0\) via the normal equations
Evaluating the moment matrices and solving for \(L_0\) gives
Forecasting \(x_1\): Note that
Applying (47.5) gives \(\mathbb{E}[x_1 \mid y_0] = A\hat{x}_0 + AL_0(y_0 - G\hat{x}_0)\), which we write as
where the Kalman gain at time 0 is
Updating the covariance: Subtracting (47.8) from (47.7) yields
Using (47.10) and \(y_0 = G x_0 + v_0\) to evaluate \(\Sigma_1 \equiv \mathbb{E}[(x_1 - \hat{x}_1)(x_1 - \hat{x}_1)' \mid y_0]\) gives
Thus \(f(x_1 \mid y_0) \sim \mathcal{N}(\hat{x}_1, \Sigma_1)\).
Collecting the time-\(0\) equations:
System (47.12) maps a mean-covariance pair \((\hat{x}_0, \Sigma_0)\) into a new pair \((\hat{x}_1, \Sigma_1)\), with auxiliary outputs \((a_0, K_0)\).
Recognising that “we are in the same situation at the start of period 1 as at the start of period 0” activates a recursion, the Kalman filter.
47.3.3. The Kalman filter recursions#
Iterating system (47.12) yields the Kalman filter for \(t \geq 0\):
Here \(K_t\) is the Kalman gain at time \(t\).
47.3.4. The matrix Riccati equation#
Substituting the expression for \(K_t\) from the second line of (47.13) into the fourth line gives an equivalent update formula:
Equation (47.14) is the matrix Riccati difference equation.
It governs the sequence of conditional covariance matrices \(\{\Sigma_t\}_{t=0}^\infty\) without reference to the observations \(\{y_t\}\).
47.4. The Gram-Schmidt process#
The random vector
is the innovation of \(y_t\) with respect to \(y^{t-1}\), the part of \(y_t\) that cannot be predicted from past observations.
Note that \(\mathbb{E} a_t a_t' = G\Sigma_t G' + R\), the matrix whose inverse appears in the Kalman gain formula (47.13).
A direct calculation using \(a_t = G(x_t - \hat{x}_t) + v_t\) shows that \(\mathbb{E} a_t a_{t-1}' = 0\) and, more generally, \(\mathbb{E}[a_t \mid a_{t-1}, \ldots, a_0] = 0\).
Note
An alternative argument from first principles: let \(H(y^t)\) denote the closed linear span of \(y^t\).
Since \(a_{t+1} = y_{t+1} - \mathbb{E}[y_{t+1} \mid y^t]\) is a least-squares error, \(a_{t+1} \perp H(y^t)\), and in particular \(a_{t+1} \perp a_t\).
Thus \(\{a_t\}\) is a white-noise process of innovations to \(\{y_t\}\).
Sometimes (47.13) is called a whitening filter: it takes the signal process \(\{y_t\}\) as input and produces the white-noise innovation process \(\{a_t\}\) as output.
The linear space \(H(a^t)\) is an orthogonal basis for the linear space \(H(y^t)\).
Rather than computing \(\mathbb{E}[x_t \mid y_{t-1}, \ldots, y_0]\) via one large regression, the Kalman filter performs a sequence of small regressions on successive orthogonal components of the basis \([a_{t-1}, \ldots, a_0]\), an instance of the Gram-Schmidt procedure.
47.6. Estimation#
47.6.1. The innovations representation#
The innovations representation emerging from the Kalman filter is
where \(\hat{x}_t = \mathbb{E}[x_t \mid y^{t-1}]\) for \(t \geq 1\) and \(\mathbb{E}[a_t a_t' \mid y^{t-1}] = G\Sigma_t G' + R \equiv \Omega_t\).
For \(t \geq 1\), \(\mathbb{E}[y_t \mid y^{t-1}] = G\hat{x}_t\) and the conditional distribution of \(y_t\) given \(y^{t-1}\) is \(\mathcal{N}(G\hat{x}_t, \Omega_t)\).
The objects \((G\hat{x}_t, \Omega_t)\) emerging from the Kalman filter recursions therefore completely characterise this conditional distribution.
47.6.2. The likelihood function#
We can factor the likelihood of a sample \((y_T, y_{T-1}, \ldots, y_0)\) as
The log conditional density of the \(m \times 1\) vector \(y_t\) is
Using (47.17) and (47.13) together, we can evaluate the likelihood (47.16) recursively for any parameter vector \(\theta\) that underlies the matrices \(A, G, C, R\).
Such calculations are at the heart of efficient strategies for computing maximum likelihood estimators of free parameters.
47.6.3. Bayesian inference#
The likelihood function is also central to Bayesian inference.
Where \(\theta\) is the parameter vector, \(y_0^T\) the data, and \(\tilde{p}(\theta)\) a prior density over \(\theta\) before seeing \(y_0^T\), Bayes’ law gives the posterior
The denominator is the marginal joint density \(f(y_0^T)\).
47.7. Vector autoregressions and the Kalman filter#
47.7.1. Convergence to a steady state#
Under conditions discussed by Anderson, Hansen, McGrattan, and Sargent (1996), iterations on the Riccati equation (47.14) converge to a time-invariant matrix \(\Sigma\) from any positive semi-definite starting value \(\Sigma_0\).
A time-invariant fixed point \(\Sigma_t = \Sigma\) of (47.14) is the covariance matrix of \(x_t\) around
where the conditioning extends over the semi-infinite past \(s \leq t-1\).
47.7.2. A time-invariant VAR#
If the fixed point \(\Sigma\) exists and we initialise the filter at \(\Sigma_0 = \Sigma\), the innovations representation (47.15) becomes time-invariant:
where \(\mathbb{E} a_t a_t' = G\Sigma G' + R\) and the steady-state Kalman gain is \(K = A\Sigma G'(G\Sigma G' + R)^{-1}\).
From (47.18) we obtain \(\hat{x}_{t+1} = (A - KG)\hat{x}_t + K y_t\).
If the eigenvalues of \(A - KG\) are bounded in modulus strictly below unity, we can solve this equation forward to get
Substituting (47.19) into the observation equation of (47.18) gives the vector autoregression
where by construction
The orthogonality conditions (47.21) identify (47.20) as a vector autoregression.
Defining the lag operator \(L\) by \(L x_{t+1} \equiv x_t\), the moving average representation deduced from (47.18) is
47.7.3. Interpreting VARs#
Equilibria of economic models (or their linear or log-linear approximations) typically take the form of state space system (47.1).
This hidden Markov model disturbs the state \(x_t\) by the \(p \times 1\) shock vector \(w_{t+1}\) and perturbs the \(m \times 1\) vector of observables \(y_t\) by the \(m \times 1\) measurement error \(v_t\).
An economic theory typically makes \(w_{t+1}\) and \(v_t\) directly interpretable as shocks to preferences, technologies, endowments, or information sets.
The state space system (47.1) represents \(\{y_t\}\) in terms of these interpretable shocks.
However, in the typical situation these shocks cannot be recovered directly from the \(y_t\)’s, even when \(A, G, C, R\) are known.
The innovations representation (47.18) represents the same stochastic process \(\{y_t\}\) in terms of the \(m \times 1\) vector \(a_t\) of innovations that would be recovered by running an infinite-order population vector autoregression.
Its role in mapping the original representation (47.1) to the VAR (47.20) makes the Kalman filter an indispensable tool for interpreting vector autoregressions.
47.8. Spectral factorization identity#
Because the original state space system (47.1) and the innovations representation (47.18) describe the same stochastic process \(\{y_t\}\), they imply two distinct formulas for the spectral density matrix of \(\{y_t\}\).
Equating those formulas yields the spectral factorization identity.
47.8.1. Two representations of the spectral density#
From the original state space system. Writing the first line of (47.1) as \(x_t = (zI - A)^{-1} C w_{t+1}\) (using the \(z\)-transform convention \(z^{-1} x_t = x_{t-1}\)), the covariance generating function of \(\{x_t\}\) is
Since \(v_t\) is orthogonal to \(x_t\), the spectral density of \(\{y_t\}\) is
From the innovations representation. The time-invariant innovations representation (47.18) gives \(y_t = [G(zI - A)^{-1}K + I]\, a_t\). Since \(a_t\) is white noise with covariance matrix \(G\Sigma G' + R\), the spectral density is also
47.8.2. The spectral factorization identity#
Equating (47.22) and (47.23) gives the spectral factorization identity:
The left side expresses \(S_y(z)\) in terms of the structural shocks \((w_{t+1}, v_t)\) and the matrices \((A, C, G, R)\).
The right side expresses the same object as a spectral factor built from the innovations \(a_t\) and the steady-state Kalman gain \(K\).
47.8.3. Connection to the Wold and autoregressive representations#
The factorization (47.24) underpins the passage from the innovations representation to the Wold moving average and to the VAR.
Wold representation. From (47.18), solving for \(\hat{x}_t\) over the semi-infinite past gives \(\hat{x}_{t+1} = (I - AL)^{-1} K a_t\), so
Autoregressive (VAR) representation. Applying the inverse of the moving-average operator in (47.25), using the identity
gives
which is the vector autoregression already stated in (47.20).
The key analytical fact behind both representations is that, under mild stability conditions, the zeros of \(\det[G(zI-A)^{-1}K + I]\) all lie inside the unit circle.
This ensures that the moving-average operator in (47.25) has a causal (one-sided) inverse, so the innovation \(a_t\) lies in the closed linear span of current and past observations \(y^t\), confirming that \(a_t\) is the true population forecast error from the VAR.
47.9. Python implementation#
We now illustrate the theory using the quantecon library, which provides
LinearStateSpace and Kalman classes that implement everything derived above.
import numpy as np
import matplotlib.pyplot as plt
import quantecon as qe
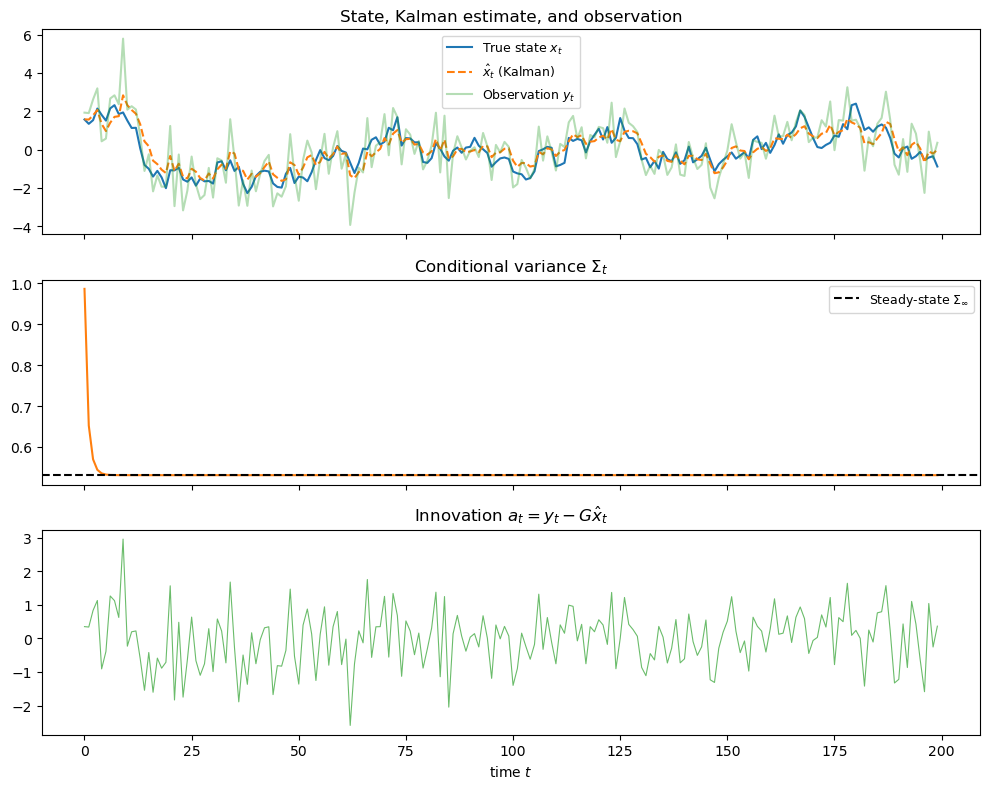
47.9.2. Convergence of the Riccati equation#
The Kalman class computes the steady-state covariance \(\Sigma_\infty\) by
solving the discrete algebraic Riccati equation directly.
Sigma_inf, K_inf = kf.stationary_values()
print(f"Steady-state covariance Σ_inf = {Sigma_inf[0, 0]:.6f}")
print(f"Kalman filter converged to Σ_t = {Sigmas[-1]:.6f}")
print(f"Steady-state Kalman gain K = {K_inf[0, 0]:.6f}")
A_minus_KG = A - K_inf @ G
eigval = np.linalg.eigvals(A_minus_KG)[0]
print(f"\nEigenvalue of (A - KG) = {eigval:.6f}")
print(f"Stable VAR: {np.abs(eigval) < 1}")
Steady-state covariance Σ_inf = 0.530899
Kalman filter converged to Σ_t = 0.530899
Steady-state Kalman gain K = 0.312110
Eigenvalue of (A - KG) = 0.587890
Stable VAR: True
47.9.3. The VAR representation#
Using (47.20), the coefficients in the infinite-order VAR representation are \(G(A - KG)^j K\) for \(j = 0, 1, 2, \ldots\)
We retrieve them via stationary_coefficients:
J = 30
var_coeffs = kf.stationary_coefficients(J, coeff_type='var')
# var_coeffs[j] gives the mxm coefficient matrix at lag j+1
lags = np.arange(1, J + 1)
coeff_values = np.array([var_coeffs[j][0, 0] for j in range(J)])
fig, ax = plt.subplots(figsize=(8, 4))
ax.stem(lags, coeff_values, basefmt=' ')
ax.set_xlabel('lag $j$')
ax.set_ylabel(r'VAR coefficient $G(A{-}KG)^{j-1}K$')
plt.tight_layout()
plt.show()
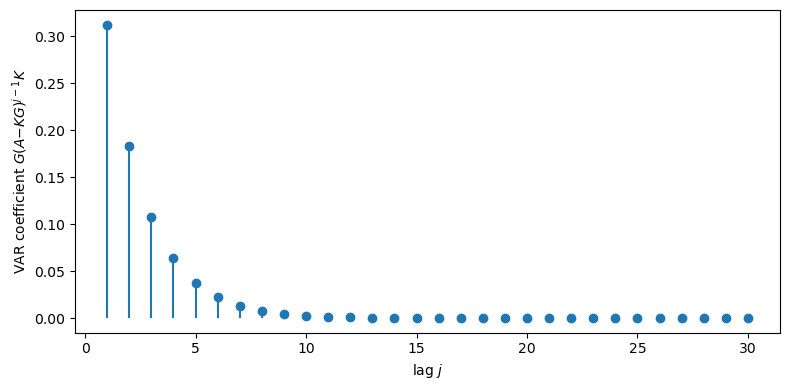
Fig. 47.2 VAR coefficients from the innovations representation#
The coefficients decay geometrically, confirming that the infinite-order VAR (47.20) is well approximated by a finite-lag truncation.
47.9.4. Likelihood evaluation#
We use (47.17) to evaluate the log-likelihood of the simulated sample.
def log_likelihood(A, C, G, R, y_data, x_hat_0, Sigma_0):
"""Evaluate the log-likelihood using the Kalman filter recursions."""
H_ = np.linalg.cholesky(R) # R = H_ @ H_.T
lss_ = qe.LinearStateSpace(A, C, G, H_, mu_0=x_hat_0, Sigma_0=Sigma_0)
kf_ = qe.Kalman(lss_)
kf_.set_state(x_hat_0, Sigma_0)
T_, m_ = y_data.shape
loglik = 0.0
for t in range(T_):
x_h = kf_.x_hat
Sig = kf_.Sigma
Omega = G @ Sig @ G.T + R # innovation covariance
a_t = y_data[t] - (G @ x_h).flatten()
sign, logdet = np.linalg.slogdet(Omega)
loglik += -0.5 * (m_ * np.log(2 * np.pi) + logdet
+ float(a_t @ np.linalg.solve(Omega, a_t)))
kf_.update(y_data[t])
return loglik
y_data_col = y_obs.reshape(-1, 1)
ll = log_likelihood(A, C, G, R,
y_data_col,
np.zeros(1), np.eye(1) * 10.0)
print(f"Log-likelihood of sample: {ll:.4f}")
Log-likelihood of sample: -325.2335
47.10. An example#
We now work through a structured example that shows how a bivariate VAR(2) fits naturally into the state space framework and how the Kalman filter delivers a Wold (innovations) representation.
47.10.1. Linear state-space system#
The state and observation equations are
with initial condition and shock distributions
47.10.2. Steady-state Riccati equation#
The steady-state error covariance matrix \(\Sigma\) satisfies
47.10.3. Kalman gain#
47.10.4. Kalman filter recursion#
Starting from an initial estimate \(\hat{x}_0\), the Kalman filter updates the state estimate via
where the innovation (prediction error) is
Substituting (47.32) into (47.31) and expanding:
47.10.5. Impulse responses of \(y_t\) to the innovations \(a_t\)#
It is useful to compute the ordinary impulse response functions of the observable vector \(y_t\) to its own innovations \(a_t\), the moving-average (Wold) representation that is the mirror image of the VAR (47.20).
From the time-invariant innovations representation (47.18)
the moving-average representation (47.25) is
Hence the impulse response of \(y_t\) to a unit innovation \(a_t\) is
These coefficients decay at the rate governed by the eigenvalues of \(A\), in contrast to the innovation-to-structural-shock responses studied later in the numerical example, which decay at the rate governed by the eigenvalues of \(A - KG\).
We can read the coefficients (47.34) directly off a quantecon
LinearStateSpace object.
We build a state-space system whose state is the filtered estimate \(\hat{x}_t\), whose single “shock” is the innovation \(a_t\) loaded through \(C = K\), and whose observation matrix is \(G\).
The
impulse_response method of that object returns the sequence \(G A^{j} K\) for
\(j = 0, 1, 2, \ldots\), which are exactly the \(\Psi_h\) for \(h \ge 1\); we prepend
\(\Psi_0 = I\) to capture the contemporaneous feed-through \(y_t = G\hat{x}_t + a_t\).
def y_to_a_irf(A, K, G, T=40):
"""
Ordinary impulse responses of the observable y_t to its own
innovations a_t in the innovations (Wold) representation
x_hat_{t+1} = A x_hat_t + K a_t
y_t = G x_hat_t + a_t.
The moving-average coefficients are
Ψ_0 = I, Ψ_h = G A^{h-1} K (h >= 1).
The h >= 1 terms come from quantecon's LinearStateSpace: loading the
innovation a_t through C = K makes its impulse_response method return
G A^j K for j = 0, 1, 2, .... We prepend Ψ_0 = I for the
contemporaneous feed-through.
Returns an array of shape (T, m, m); entry [h, i, j] is the response
of observable i at horizon h to a unit innovation in component j.
"""
n, m = A.shape[0], G.shape[0]
lss = qe.LinearStateSpace(A, K, G, np.zeros((m, m)), mu_0=np.zeros(n))
_, ycoef = lss.impulse_response(j=T - 2) # [GK, GAK, GA^2K, ...]
Psi = np.empty((T, m, m))
Psi[0] = np.eye(m) # contemporaneous response
for h in range(1, T):
Psi[h] = ycoef[h - 1]
return Psi
47.10.6. Augmented state-space representation#
We want to express the innovations \(a_t\) as a function of the state shocks \(w_{t+1}\) and the measurement error \(v_t\).
To accomplish this, we start by stacking the true state \(x_t\) and the filter estimate \(\hat{x}_t\) into an augmented state vector that obeys
47.10.7. Bivariate VAR(2) in state-space form#
Consider two observable series \(r_t\) and \(z_t\).
Stack them into the state vector \(x_t = (r_t,\; r_{t-1},\; z_t,\; z_{t-1})'\).
We posit the VAR(2) state-transition equation:
We consider two possible observation equations.
The first is a bivariate observation of \(r_t\) and \(z_t\):
The second is a univariate observation of \(r_t\):
For the bivariate observation case, the Wold representation is
where \(\mathbb{E} a_t a_t' = G \Sigma G' + R\) and \(L\) is the lag operator.
The innovation expressed in terms of the augmented state is
For the scalar (\(1 \times 1\)) case with a single observable \(r_t\), the observation matrix \(G_1\) is the first row of \(G\) and the scalar gain \(K_1\) is the outcome of the Kalman filter for that case. The univariate Wold representation is
where the univariate innovation \(u_t\) is given by
and \(\mathbb{E} u_t^2 = G_1 \check \Sigma G_1' + R_{11}\), and \(\check \Sigma\) is the steady-state covariance of the augmented state vector associated with \(G_1, R_{11}\).
47.10.8. Numerical example: impulse responses of innovations#
We now set specific parameter values and compute the impulse response functions of the Kalman innovations (\(a_t\) in System 1 and \(u_t\) in System 2) to the two structural shocks \(w_{1,t+1}\) and \(w_{2,t+1}\).
The key object is not the response of the observable \(y_t\) to the shocks, but rather the response of the innovation that the Kalman filter produces.
In System 1, \(a_t\) is the \(2 \times 1\) forecast error of \((r_t, z_t)'\) given the filter’s estimate; in System 2, \(u_t\) is the scalar forecast error of \(r_t\) given the filter’s estimate based on the \(r_t\) history alone.
The parameter values are:
These give the \(4 \times 4\) transition matrix and \(4 \times 2\) shock-loading matrix
System 1 uses the bivariate observation equation (47.37), so \(G\) selects \((r_t, z_t)'\) from the state and the innovation \(a_t\) is \(2 \times 1\).
System 2 uses the univariate observation equation (47.38), so \(G_1\) selects only \(r_t\) and the innovation \(u_t\) is scalar.
Because the innovation equals \(a_t = G(x_t - \hat{x}_t) + v_t\), a unit shock \(w_j\) propagates through the augmented state \((x_t', \hat{x}_t')'\).
A straightforward calculation using the augmented recursion (47.35) shows that the impulse response of the innovation at horizon \(h \geq 0\) is
where \(e_j\) is the \(j\)-th column of \(I_2\) and \(K\) is the appropriate steady-state Kalman gain (System 1 uses \(K\) from the bivariate filter; System 2 uses \(K_1\) from the univariate filter).
At \(h=0\) the shock hits and the innovation equals \(GCe_j\); for \(h \geq 1\) the response decays at the rate governed by the eigenvalues of \(A - KG\).
import numpy as np
import matplotlib.pyplot as plt
import quantecon as qe
# -- Parameters ---------------------------------------------------------------
d1, d2, d3, d4 = 0.80, 0.05, 0.75, -.72
delta1, delta2, delta3, delta4 = 0.00, 0.00, 0.75, 0.20
c11, c12, c21, c22 = 1.0, 0.0, 0.0, 1.0
sigma_v = 0.01 # sqrt(0.0001)
# -- Shared matrices -----------------------------------------------------------
A_var = np.array([[d1, d2, d3, d4 ],
[1.0, 0.0, 0.0, 0.0 ],
[delta1, delta2, delta3, delta4],
[0.0, 0.0, 1.0, 0.0 ]])
C_var = np.array([[c11, c12],
[0.0, 0.0],
[c21, c22],
[0.0, 0.0]])
# -- System 1: bivariate observation ------------------------------------------
G_biv = np.array([[1.0, 0.0, 0.0, 0.0],
[0.0, 0.0, 1.0, 0.0]])
H_biv = sigma_v * np.eye(2) # H @ H.T = 0.0001 * I_2
lss_biv = qe.LinearStateSpace(A_var, C_var, G_biv, H_biv,
mu_0=np.zeros(4), Sigma_0=np.eye(4))
kf_biv = qe.Kalman(lss_biv)
Sigma_biv, K_biv = kf_biv.stationary_values()
print("System 1 - steady-state Kalman gain K (4x2):")
print(np.round(K_biv, 5))
# -- System 2: univariate observation -----------------------------------------
G_uni = np.array([[1.0, 0.0, 0.0, 0.0]])
H_uni = np.array([[sigma_v]]) # H @ H.T = 0.0001
lss_uni = qe.LinearStateSpace(A_var, C_var, G_uni, H_uni,
mu_0=np.zeros(4), Sigma_0=np.eye(4))
kf_uni = qe.Kalman(lss_uni)
Sigma_uni, K_uni = kf_uni.stationary_values()
print("\nSystem 2 - steady-state Kalman gain K (4x1):")
print(np.round(K_uni, 5))
System 1 - steady-state Kalman gain K (4x2):
[[7.9987e-01 7.4987e-01]
[9.9990e-01 0.0000e+00]
[1.0000e-05 7.4994e-01]
[0.0000e+00 9.9990e-01]]
System 2 - steady-state Kalman gain K (4x1):
[[0.72306]
[0.99994]
[0.31829]
[0.30984]]
# -- Covariance comparisons ----------------------------------------------------
# State-noise covariance CC' versus innovation covariance G Σ G' + R (System 1)
CC_prime = C_var @ C_var.T
R_biv = (sigma_v**2) * np.eye(2)
innov_cov_biv = G_biv @ Sigma_biv @ G_biv.T + R_biv
print("State-noise covariance CC' (4x4):")
print(np.round(CC_prime, 6))
print("\nSystem 1 - innovation covariance GΣG' + R (2x2):")
print(np.round(innov_cov_biv, 6))
# Steady-state state covariance: System 1 (Σ_biv) vs System 2 (Σ_uni)
print("\nSystem 1 - steady-state state covariance Σ (4x4):")
print(np.round(Sigma_biv, 6))
print("\nSystem 2 - steady-state state covariance Σ_check (4x4):")
print(np.round(Sigma_uni, 6))
print("\nDifference Σ_check - Σ (System 2 minus System 1):")
print(np.round(Sigma_uni - Sigma_biv, 6))
State-noise covariance CC' (4x4):
[[1. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 1. 0.]
[0. 0. 0. 0.]]
System 1 - innovation covariance GΣG' + R (2x2):
[[1.000272e+00 4.200000e-05]
[4.200000e-05 1.000160e+00]]
System 1 - steady-state state covariance Σ (4x4):
[[1.000172e+00 8.000000e-05 4.200000e-05 7.500000e-05]
[8.000000e-05 1.000000e-04 0.000000e+00 0.000000e+00]
[4.200000e-05 0.000000e+00 1.000060e+00 7.500000e-05]
[7.500000e-05 0.000000e+00 7.500000e-05 1.000000e-04]]
System 2 - steady-state state covariance Σ_check (4x4):
[[1.578696e+00 7.200000e-05 4.891690e-01 6.781580e-01]
[7.200000e-05 1.000000e-04 3.200000e-05 3.100000e-05]
[4.891690e-01 3.200000e-05 6.671917e+00 6.060303e+00]
[6.781580e-01 3.100000e-05 6.060303e+00 6.520354e+00]]
Difference Σ_check - Σ (System 2 minus System 1):
[[ 5.785240e-01 -8.000000e-06 4.891270e-01 6.780830e-01]
[-8.000000e-06 0.000000e+00 3.200000e-05 3.100000e-05]
[ 4.891270e-01 3.200000e-05 5.671857e+00 6.060228e+00]
[ 6.780830e-01 3.100000e-05 6.060228e+00 6.520254e+00]]
47.10.8.1. Impulse responses of \(y_t\) to the innovations \(a_t\)#
We now apply the helper y_to_a_irf defined above to compute the ordinary
impulse responses (47.34) of the observable \(y_t\) to its own
innovations \(a_t\), for both System 1 (bivariate, so \(a_t\) is \(2 \times 1\)) and
System 2 (univariate, so \(u_t\) is scalar).
T_irf = 40
horizons = np.arange(T_irf)
Psi_biv = y_to_a_irf(A_var, K_biv, G_biv, T_irf) # System 1: (T, 2, 2)
Psi_uni = y_to_a_irf(A_var, K_uni, G_uni, T_irf) # System 2: (T, 1, 1)
obs_labels = [r'$r_t$', r'$z_t$']
innov_labels = [r'$a_{1,t}$', r'$a_{2,t}$']
# -- Figure: System 1 - responses of y_t = (r_t, z_t)' to its innovations a_t --
fig, axes = plt.subplots(2, 2, figsize=(10, 6), sharex=True)
for i, obs in enumerate(obs_labels):
for j, inn in enumerate(innov_labels):
ax = axes[i, j]
ax.plot(horizons, Psi_biv[:, i, j], lw=1.8)
ax.axhline(0, color='k', lw=0.6, ls='--')
ax.set_title(f'{obs} to {inn}', fontsize=9)
if i == 1:
ax.set_xlabel('horizon $h$')
if j == 0:
ax.set_ylabel('response')
plt.tight_layout()
plt.show()
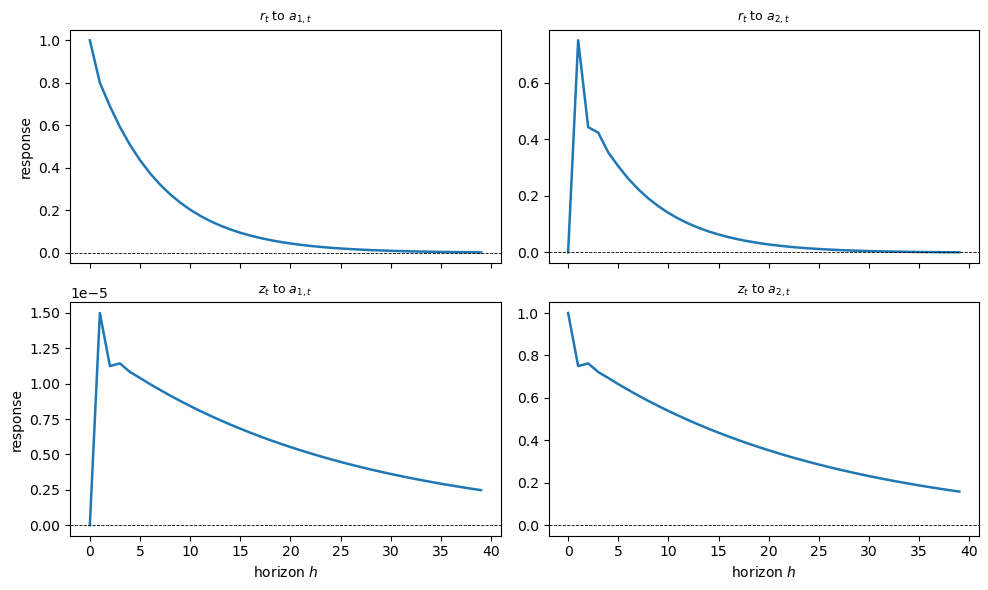
Fig. 47.3 System 1: IRFs of \(y_t = (r_t, z_t)\) to its innovations \(a_t\)#
fig, ax = plt.subplots(figsize=(7, 3.5))
ax.plot(horizons, Psi_uni[:, 0, 0], lw=1.8)
ax.axhline(0, color='k', lw=0.6, ls='--')
ax.set_xlabel('horizon $h$')
ax.set_ylabel('response')
plt.tight_layout()
plt.show()
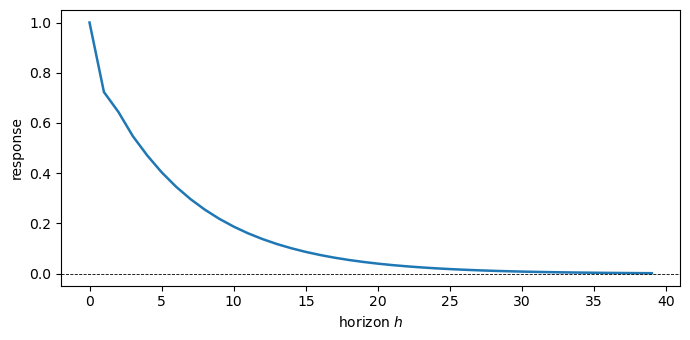
Fig. 47.4 System 2: IRF of \(r_t\) to its innovation \(u_t\)#
At horizon \(h = 0\) each innovation passes one-for-one into its own component of \(y_t\), the contemporaneous response equals the identity matrix \(\Psi_0 = I\), so the diagonal panels start at \(1\) and the off-diagonal panels start at \(0\).
For \(h \ge 1\) the responses propagate through the state matrix \(A\) and decay geometrically, tracing out the Wold moving-average representation of the bivariate (System 1) and univariate (System 2) processes.
47.10.8.2. Impulse responses of the innovations to the structural shocks#
def innovation_irf(A, K, G, C, T=40):
"""
Impulse responses of the Kalman innovation to each structural shock.
The innovation at horizon h to a unit shock e_j is
G (A - KG)^h C e_j, h = 0, 1, ..., T-1.
Returns irf of shape (T, n_a, n_w).
"""
AKG = A - K @ G
n_a = G.shape[0]
n_w = C.shape[1]
irf = np.zeros((T, n_a, n_w))
x = C.copy() # (A-KG)^0 @ C at h = 0
for h in range(T):
irf[h] = G @ x
x = AKG @ x
return irf
T_irf = 40
horizons = np.arange(T_irf)
irf_biv = innovation_irf(A_var, K_biv, G_biv, C_var, T_irf) # (T, 2, 2)
irf_uni = innovation_irf(A_var, K_uni, G_uni, C_var, T_irf) # (T, 1, 2)
shock_labels = [r'Shock $w_{1,t+1}$', r'Shock $w_{2,t+1}$']
innov_biv_lbl = [r'$a_{1,t}$', r'$a_{2,t}$']
# -- Figure 1: System 1 - innovation IRFs --------------------------------------
fig, axes = plt.subplots(2, 2, figsize=(10, 6), sharex=True)
for j, shock in enumerate(shock_labels):
for i, albl in enumerate(innov_biv_lbl):
ax = axes[i, j]
ax.plot(horizons, irf_biv[:, i, j], lw=1.8)
ax.axhline(0, color='k', lw=0.6, ls='--')
ax.set_title(f'System 1 - {albl} to {shock}', fontsize=9)
ax.set_xlabel('horizon $h$')
if j == 0:
ax.set_ylabel('innovation response')
plt.suptitle(r'System 1: IRFs of innovation $a_t$ to structural shocks',
fontsize=11)
plt.tight_layout()
plt.show()
# -- Figure 2: System 2 - innovation IRFs --------------------------------------
fig, axes = plt.subplots(1, 2, figsize=(10, 3.5))
for j, shock in enumerate(shock_labels):
axes[j].plot(horizons, irf_uni[:, 0, j], lw=1.8)
axes[j].axhline(0, color='k', lw=0.6, ls='--')
axes[j].set_title(f'System 2 - $u_t$ to {shock}', fontsize=9)
axes[j].set_xlabel('horizon $h$')
axes[0].set_ylabel('innovation response')
plt.suptitle(r'System 2: IRFs of innovation $u_t$ to structural shocks',
fontsize=11)
plt.tight_layout()
plt.show()
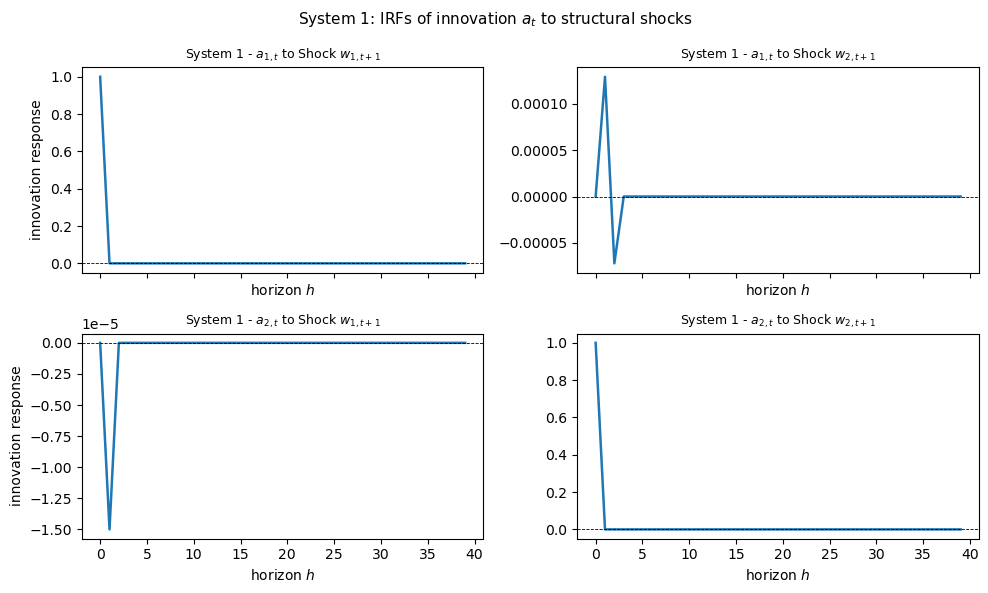
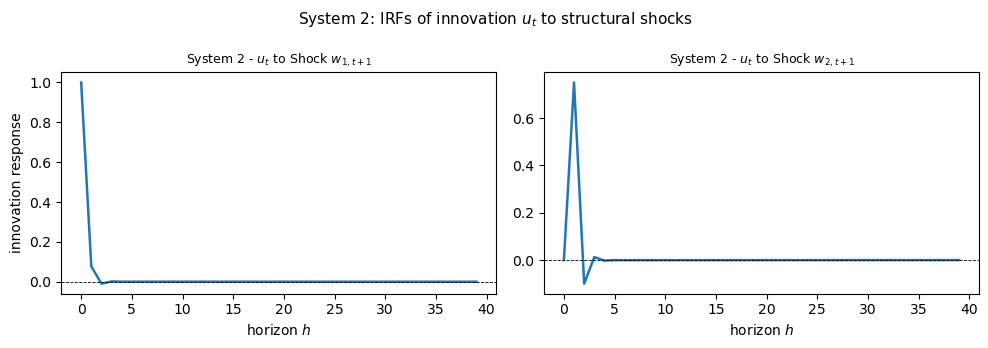
The two sets of innovation impulse responses illustrate an important point.
In System 1 the filter uses both \(r_t\) and \(z_t\), so \(a_t\) is \(2 \times 1\) and its response to each shock is a pair of numbers at every horizon.
In System 2 only \(r_t\) is observed, so \(u_t\) is scalar and carries less information about the two-dimensional shock vector.
Because \(K\) differs across the two systems, the decay matrix \(A - KG\) differs as well, so the innovation IRFs \(G(A-KG)^h C e_j\) differ across the two systems even though the structural DGP is identical.
The covariance comparisons printed above reveal two further insights.
State-noise \(CC'\) vs. innovation covariance \(G\Sigma G' + R\) (System 1).
The matrix \(CC'\) is the unconditional covariance contributed by the structural shocks to the state transition in one period.
The innovation covariance \(G\Sigma G' + R\) is the covariance of the one-step forecast error in the observable vector after the Kalman filter has processed all available information.
In this example \(GCC'G'\) has diagonal entries equal to \(1\).
The printed innovation covariance has diagonal entries slightly above \(1\) because it also contains residual uncertainty from estimating the hidden state and the small measurement-error variance \(R = 0.0001 I_2\).
Thus \(G\Sigma G' + R\) should not be compared directly with \(GCC'G'\) as a strict variance reduction.
The variance reduction created by filtering is measured relative to the broader forecast-error covariance before conditioning on the available observations.
System 1 covariance \(\Sigma\) vs. System 2 covariance \(\check\Sigma\).
Restricting observations to \(r_t\) alone (System 2) yields less information about the hidden state, so the filter is less precise: \(\check\Sigma \succeq \Sigma\), i.e., the difference \(\check\Sigma - \Sigma\) is positive semi-definite.
The printed difference matrix confirms this ordering for our parameter values.
47.11. Exercises#
Exercise 47.1
Consider the scalar AR(1) state space system used above with \(\rho = 0.9\), \(\sigma_w = 0.5\), \(\sigma_v = 1.0\).
Derive an algebraic expression for the steady-state conditional variance \(\Sigma_\infty\) by solving the scalar Riccati equation (47.14) at its fixed point \(\Sigma_{t+1} = \Sigma_t = \Sigma\).
Show that \(\Sigma\) satisfies a quadratic equation, find its positive root, and
verify numerically that your formula matches kf.Sigma_infinity.
Solution
Setting \(\Sigma_{t+1} = \Sigma_t = \Sigma\) in the scalar version of (47.14) with \(A = \rho\), \(CC' = \sigma_w^2\), \(GG' = 1\), \(R = \sigma_v^2\):
Multiplying through by \(\Sigma + \sigma_v^2\) and rearranging:
Taking the positive root of this quadratic:
rho_, sigma_w_, sigma_v_ = 0.9, 0.5, 1.0
b = sigma_v_**2 * (1 - rho_**2) - sigma_w_**2
discriminant = b**2 + 4 * sigma_v_**2 * sigma_w_**2
Sigma_formula = (-b + np.sqrt(discriminant)) / 2
A_ = np.array([[rho_]])
C_ = np.array([[sigma_w_]])
G_ = np.array([[1.0]])
R_ = np.array([[sigma_v_**2]])
H_ = np.array([[sigma_v_]]) # R_ = H_ @ H_.T
lss_ = qe.LinearStateSpace(A_, C_, G_, H_, mu_0=np.zeros(1), Sigma_0=np.eye(1))
kf_ = qe.Kalman(lss_)
print(f"Analytical Σ_inf = {Sigma_formula:.8f}")
print(f"Numerical Σ_inf = {kf_.Sigma_infinity[0, 0]:.8f}")
Analytical Σ_inf = 0.53089919
Numerical Σ_inf = 0.53089919
Exercise 47.2
Bivariate example.
Consider a two-dimensional state with a one-dimensional observation:
(a) Simulate \(T = 500\) observations from this system starting from a diffuse prior.
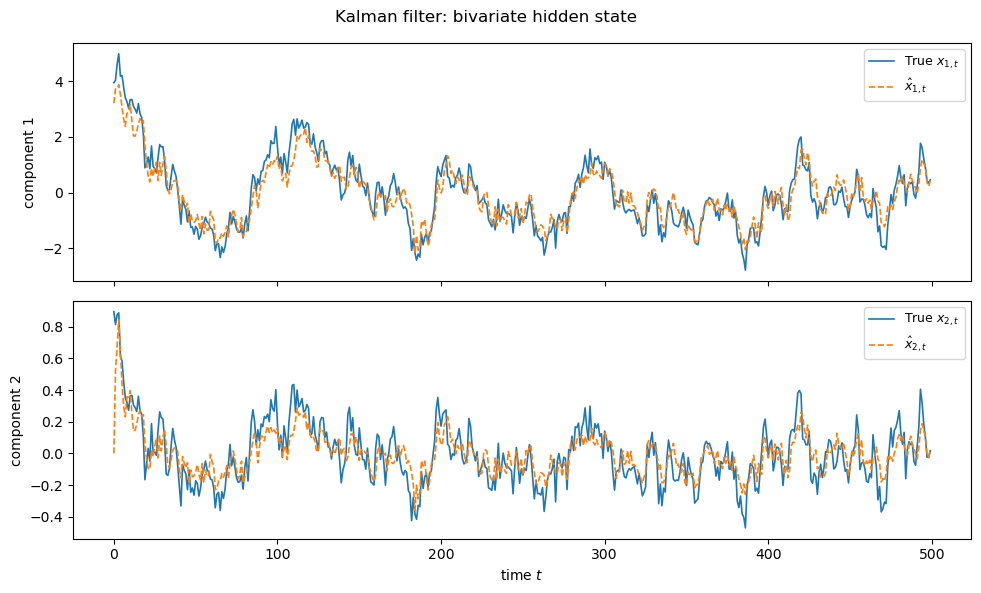
(b) Run the Kalman filter and plot both components of \(\hat{x}_t\) against the true hidden state path.
© Compute and report the steady-state covariance \(\Sigma_\infty\) and Kalman gain \(K_\infty\).
(d) Check that the eigenvalues of \(A - K_\infty G\) lie strictly inside the unit circle, confirming that the VAR representation (47.20) is stable.
Solution
A2 = np.array([[0.9, 0.1],
[0.0, 0.8]])
C2 = np.array([[0.4],
[0.1]])
G2 = np.array([[1.0, 0.0]])
R2 = np.array([[0.5]])
H2 = np.array([[np.sqrt(0.5)]]) # R2 = H2 @ H2.T
lss2 = qe.LinearStateSpace(A2, C2, G2, H2,
mu_0=np.zeros(2),
Sigma_0=np.eye(2) * 5.0)
kf2 = qe.Kalman(lss2)
kf2.set_state(np.zeros(2), np.eye(2) * 5.0)
T2 = 500
x2_path, y2_path = lss2.simulate(ts_length=T2, random_state=0)
x_hats2 = np.zeros((T2, 2))
for t in range(T2):
kf2.update(y2_path[:, t])
x_hats2[t] = kf2.x_hat.ravel()
fig, axes = plt.subplots(2, 1, figsize=(10, 6), sharex=True)
for i, ax in enumerate(axes):
ax.plot(x2_path[i, :T2], lw=1.2, label=f'True $x_{{{i+1},t}}$')
ax.plot(x_hats2[:, i], lw=1.2, ls='--', label=rf'$\hat{{x}}_{{{i+1},t}}$')
ax.legend(fontsize=9)
ax.set_ylabel(f'component {i+1}')
axes[1].set_xlabel('time $t$')
plt.suptitle('Kalman filter: bivariate hidden state')
plt.tight_layout()
plt.show()
# (c) Steady-state values
Sigma2_inf, K2_inf = kf2.stationary_values()
print("Steady-state covariance Σ_inf:")
print(np.round(Sigma2_inf, 5))
print("\nSteady-state Kalman gain K_inf:")
print(np.round(K2_inf, 5))
# (d) Eigenvalues of A - K_inf G
AKG2 = A2 - K2_inf @ G2
eigvals2 = np.linalg.eigvals(AKG2)
print(f"\nEigenvalues of A - K_inf G: {np.round(eigvals2, 5)}")
print(f"Stable VAR: {np.all(np.abs(eigvals2) < 1)}")
Steady-state covariance Σ_inf:
[[0.32854 0.07219]
[0.07219 0.0166 ]]
Steady-state Kalman gain K_inf:
[[0.36559]
[0.06971]]
Eigenvalues of A - K_inf G: [0.56394 0.77047]
Stable VAR: True
Exercise 47.3
Likelihood and parameter estimation.
Using the scalar model from the main text with true parameters \((\rho, \sigma_w, \sigma_v) = (0.9, 0.5, 1.0)\):
(a) Simulate \(T = 300\) observations.
(b) Write a function that evaluates the log-likelihood as a function of \(\rho \in (0, 1)\), holding \(\sigma_w = 0.5\) and \(\sigma_v = 1.0\) fixed, and plot the log-likelihood against \(\rho\) for a grid of values.
© Locate the maximum numerically and check that it is close to the true value \(\rho = 0.9\).
Solution
# True parameters
rho_true, sw_true, sv_true = 0.9, 0.5, 1.0
A_t = np.array([[rho_true]])
C_t = np.array([[sw_true]])
G_t = np.array([[1.0]])
R_t = np.array([[sv_true**2]])
H_t = np.array([[sv_true]]) # R_t = H_t @ H_t.T
lss_t = qe.LinearStateSpace(A_t, C_t, G_t, H_t,
mu_0=np.zeros(1), Sigma_0=np.eye(1))
_, y_sim = lss_t.simulate(ts_length=300, random_state=7)
y_sim = y_sim.T # shape (300, 1)
def ll_rho(rho_val):
A_ = np.array([[rho_val]])
C_ = np.array([[sw_true]])
G_ = np.array([[1.0]])
R_ = np.array([[sv_true**2]])
return log_likelihood(A_, C_, G_, R_, y_sim,
np.zeros(1), np.eye(1) * 10.0)
rho_grid = np.linspace(0.5, 0.99, 60)
ll_vals = np.array([ll_rho(r) for r in rho_grid])
rho_mle = rho_grid[np.argmax(ll_vals)]
fig, ax = plt.subplots(figsize=(8, 4))
ax.plot(rho_grid, ll_vals)
ax.axvline(rho_true, color='k', ls='--', label=f'True ρ = {rho_true}')
ax.axvline(rho_mle, color='tab:red', ls=':', label=f'MLE ρ_hat = {rho_mle:.3f}')
ax.set_xlabel(r'$\rho$')
ax.set_ylabel('log-likelihood')
ax.set_title('Profile log-likelihood as a function of $\\rho$')
ax.legend()
plt.tight_layout()
plt.show()
print(f"True ρ = {rho_true}, MLE ρ_hat = {rho_mle:.4f}")
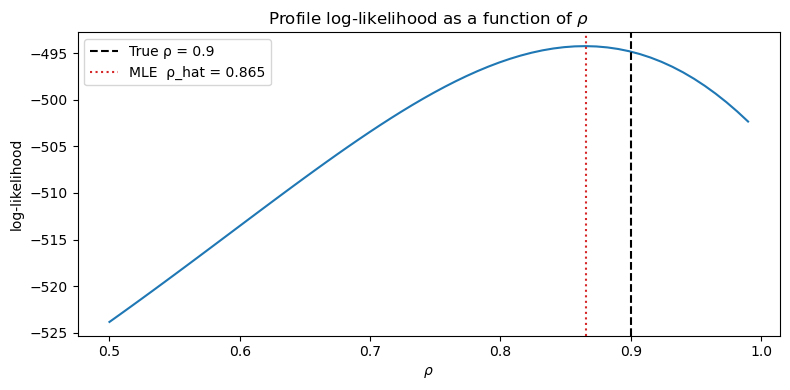
True ρ = 0.9, MLE ρ_hat = 0.8654